
The world of geospatial data analysis is rapidly evolving, with cloud-native solutions becoming increasingly popular for processing and managing large datasets. In this blog post, we discuss the benefits of cloud-native geospatial file formats and how they differ from traditional approaches, as well as the challenges and opportunities that lie ahead in this domain.
The Shift to Cloud-Native Geospatial Data
Traditional geospatial file formats, such as NetCDF, HDF5, and GeoTIFF, require users to download entire files before conducting any analysis. While these files may be rich in metadata, users are limited by their personal machines’ network and storage capacities. As data grows in volume and complexity, this approach becomes increasingly unsustainable.
Cloud-native geospatial solutions, on the other hand, allow users to access and analyze data without depending on their local machine’s storage. This means that anyone with a network connection can run the same analysis without downloading large datasets. There are two core implementations of cloud-native: data stored with co-located compute and data stored in cloud-optimized formats. Both help minimize the amount of data that needs to be transferred across networks.
Co-Located Compute vs. Cloud-Optimized Formats
Data stored with a co-located compute server means that storage and compute servers are located in close physical proximity, often in the same data center or server. This reduces latency to access and process the data because there is less physical distance for data to travel.
Cloud-optimized formats, on the other hand, have metadata identifying data chunks based on various parameters, such as spatial extent, temporal extent, and data variable. This allows for “lazily loading” data, where client libraries first read the metadata and only fetch a subset of the raw data via HTTP range requests. These formats enable parallel access and take advantage of cloud services, making computing power previously available only via supercomputers accessible to all.
Using both techniques: co-located compute and cloud-optimized formats allows the best of both techniques to gain highly efficient big data processing systems.
Example Cloud Optimized GeoTIFFs (COGs)
Cloud Optimized GeoTiffs (COGs) are a game-changer for cloud-based geospatial workflows, as they allow for efficient data streaming and enable fully cloud-based processes. This means that COG-aware software can stream only the necessary portions of data, resulting in faster access times and reduced data copying.
Designed specifically for cloud-based workflows and storage, COGs offer numerous benefits for geospatial data users. They can be served from HTTP servers, S3 storage, or other object storage system, and they demonstrate impressive performance even when tested from a network drive or mount point.
Not only do COGs enhance cloud-based workflows, but they also provide value outside the cloud by speeding up productivity in various ways. For example,
COGs impact storage costs in cloud-based geospatial workflows by requiring less storage for the same resolution, resulting in savings of 40%-80%. Also, COGs are less power-hungry to process, requiring up to 10x less processing power than traditional Geotiffs.
Example: GEOParquet Files
GeoParquet is a new file format that uses the Apache Parquet file format as it’s base, and adds support for geospatial vector data such as points, lines, and polygons. The Parquet file format is optimized for cloud computing and was designed for efficient data storage and retrieval, providing efficient data compression and encoding schemes. It is designed to support efficient compression and encoding schemes, which result in lower storage costs for data files and maximizes the effectiveness of data queries
GeoParquet files have several benefits over other geospatial data file formats:
- The file size of GeoParquet data is quite small compared to popular formats like GeoPackage, Shapefiles, GeoJSON, and Flatgeobuf, often a half, a third, or even less of the size. GeoParquet is designed to support very efficient compression and encoding schemes, which result in lower storage costs for data files and maximizes the effectiveness of data queries
- GeoParquet provides support for data partitioning, which enables geospatial partitions.
- GeoParquet is optimized for performance and is efficient in both storage and processing, making it ideal for datasets with many columns and use cases that involve selecting and filtering data.
- Some tests show that when compared to reading a CSV, GeoParquet files can make gains anywhere from 10x to 50x speed
Related article: The Benefits of Cloud Computing and Data Storage for Scientific Research
Example: Zarr and GEOZarr
The Zarr file format is an open-source specification for the storage of N-dimensional arrays and associated metadata. It organizes N-dimensional data as a hierarchy of groups (datasets) and arrays (variables within a dataset). The format is designed to be chunked, compressed, and efficient for both read and write access. Zarr stores metadata using .json text files and array data using binary files.
GEOZarr is a geospatial extension to the Zarr specification. It provides a way to store and access geospatial data in the Zarr format. The GEOZarr specification defines a set of conventions for storing geospatial metadata, such as coordinate reference systems, spatial extents, and resolutions. It also defines a set of conventions for chunking and compression that are optimized for geospatial data.
ZARR and GEOZarr have several benefits over other geospatial file formats, including:
- Efficient storage: Zarr is designed to be chunked, compressed, and efficient for both read and write access. It is an effective way to store large datasets, and it has gained popularity among the scientific community due to its flexibility and performance.
- Flexibility: Zarr provides a hierarchical structure for storing N-dimensional arrays and associated metadata. It organizes N-dimensional data as a hierarchy of groups (datasets) and arrays (variables within a dataset). This makes it easy to organize and access large datasets.
- Parallel reading: The Zarr format supports reading subarrays from cloud storage in parallel, which has the potential to speed up queries. This can lead to faster processing times and improved performance.
- Optimized chunking and compression: GEOZarr defines a set of conventions for chunking and compression that are optimized for geospatial data. This can lead to improved performance when working with large geospatial datasets.
- Open-source: Zarr is an open-source specification for the storage of N-dimensional arrays and associated metadata. This means that it is freely available and can be modified and extended by the community.
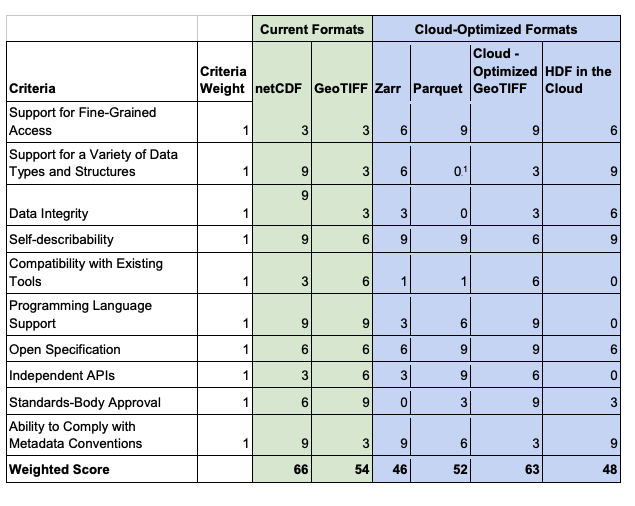
2020 NASA Study of Cloud Optimized File Formats
In 2020, NASA performed a helpful analysis of some cloud-native geospatial formats. Their end evaluation score of different file formats is shown in the table below. Note that the weighted scores could easily be changed, such as ZARR receiving OGC’s endorsement as a community standard (this took place after after NASA’s paper was written).
Challenges and Opportunities in Cloud-Native Geospatial
While storing data in the cloud is a significant step forward, there are still challenges to overcome. Data discovery remains a significant obstacle, as users must register with multiple data providers to access various datasets. Additionally, although cloud-native formats have seen success in certain areas, there is still work to be done in consolidating on cloud-optimized data access approaches.
One promising development is the wide adoption of the SpatioTemporal Asset Catalog (STAC) standard, which provides a foundation for building diverse and rich applications. By users and data providers converging on STAC and improving consistency in STAC catalogs, it may be possible to create a more streamlined and accessible system for managing geospatial data in the cloud.
The Future of Cloud-Native Geospatial Data
As the field of cloud-native geospatial data continues to evolve, there are many opportunities for innovation and improvement. By focusing on the development of cloud-native format paradigms, creating cloud-optimized data stores from the outset, and fostering a rich and common metadata standard, it is possible to create a more interoperable and scalable system for managing and processing geospatial data.
In conclusion, cloud-native geospatial file formats offer numerous benefits over traditional approaches, enabling more efficient and accessible data analysis. As the field continues to develop and innovate, we can expect to see even more advancements in this area, leading to a more connected and data-driven world.
Next Steps
Round Table Environmental Informatics (RTEI) is a consulting firm that helps our clients to leverage digital technologies for environmental analytics. We offer free consultations to discuss how we at RTEI can help you.

